
Find out how Zai took an eight year old monolithic platform that was slow, manual, and costly and built a fully scalable digital platform that connects all the data dots across our business. Now, we get the big picture view, allowing us to holistically see how our business is running.
At Zai, our mission is to help businesses automate their payment workflows. We’ve grown at a rapid pace, from a start-up in Melbourne to a global enterprise business. As we’ve expanded our services to more platforms in new industries and geographies, our data and analytical requirements have become increasingly complex. Analysing this data is paramount for leading innovation and unlocking growth opportunities. Due to the unique nature of our requirements, we simply could not utilise the analytical tools that we had in place. Therefore, we set out to build a data platform from the ground up, enabling us to define our business strategies through effective use of data.
The journey
Our business use cases
Data is no longer just a technical strategy in most modern organisations. We found a number of business use cases which required that the data platform be built out. We prioritised those associated with risk and finance to start with. Our transaction monitoring system, billing and reconciliation solutions are all built on the data platform. These use cases helped us get a holistic view of the current pain points and the opportunities a new data platform presents to the business. We started by asking the basic questions, and followed the below plan;
- Formulate the project’s objectives and key results. For example, reduce the execution time for all the existing reports down to half.
- Categorise big chunks of work on a roadmap with scope and delivery timelines.
- Break down the chunks into smaller tasks to work on.
- From this, we were able to decide what we wanted to do and the things that had to be descoped for the first pass of the deliverable. We’d arrived at our MVP.
Consolidating information into a data lake
As we worked further on the use cases, we answered the important questions including;
- “Where does the data come from? What data is more important to the business than others?”
- “How can we extract the required information into a data lake?”
- “How can we make it consumable?”
- “How do we integrate with other sources of data?”
Once we listed the key data sources, the next step was to create proof of concepts around extracting the data. We needed a data architecture to bring it all together and expose it to the users.
Data platform architecture and guiding principles
As a cloud native digital payments company, building our data lake in the cloud was a no brainer. In the first iteration, we adopted a super hard core KISS (Keep it Simple, Stupid) approach. Some of the guiding principles which helped us through the journey were to keep it:
- Serverless
- Event driven
- Immutable
- Low cost
- Low maintenance
- Low latency
- Automation first
- Open source
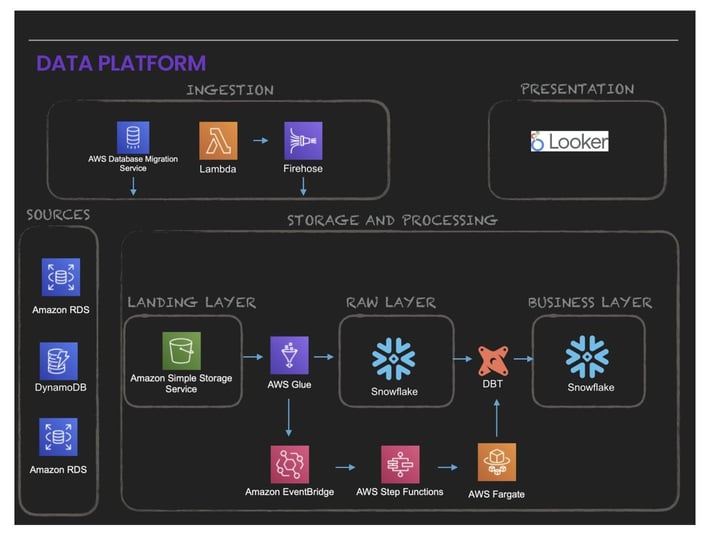
This resulted in the following three layers which make up the data platform:
- Ingestion: Consisting of DMS, Kinesis Firehose, Lambda to extract data and push it out to S3.
- Storage and Processing: Consisting of using AWS Glue, Eventbridge, Step Function, Fargate, DBT and Snowflake. These are grouped into three layers:
- Landing Layer: where the data lands in S3 in the source format (whatever formats the source supports).
- Raw Layer: optimised for consumption by those SQL fanatics.
- Business Layer: optimised for consumption by downstream applications, BI tools, business users and other data services. - Presentation: Consisting primarily of Looker which serves the Business Intelligence needs of end users.
The below diagram illustrates these layers:
One unified data model
A unified data model integrates data from multiple sources and provides a single point of entry for all analytics and data services needs. We answered questions which helped to give a solid modelling foundation, including:
- “How can we transform data which makes retrieval easier?”
- “How can we improve the data quality?”
- “How can we improve the performance?”
- “What are the user query patterns we could expect from downstream users of our applications?”
We decided not to over-engineer the modelling problem, so we used the KISS framework again.
Finalising the pieces of the puzzle
We decided to implement items like data quality monitoring and alerting as part of the next phase and focus fully on developing an initial foundation, pumping data on a daily basis from our key sources into the data lake focussing on one use case.
We were finally in a position to go live with:
- 10 Data Pipelines
- 4 Data Sources
- 1 Million events daily
- 20 daily active users
And, the end result? We saw report execution times reduce by a staggering 97%!
The following DBT lineage graph shows all the datasets maintained and built daily:
What’s next?
This is only the beginning. The first phase has given us a solid foundation to build more data services. When looking ahead, we’ve defined two strategic pillars to build upon; Grow and Innovate:
Grow:
- We will build more use cases for Finance, Payments, Risk and Compliance, Marketing and Operations. This goal ensures we have a robust, whole business view of all data.
- As we merge with CurrencyFair, we’re scoping how to integrate data from their business. Planning and analysis is well underway.
- We’ll scale our platform to support internal data services including data quality monitoring; improving the latency of data so that business functions have more visibility.
Innovate:
- As part of our strategic thinking of data as a product, we will lay the foundations for an advanced analytics platform and leverage artificial intelligence and machine learning which will eventually help us better serve our customers both internally and externally.
Stay tuned for part two of the series as we share more about our learnings.


